DPPD Masterclass Reflections
Andreas Pawelke & Basma Albanna
Together with the GIZ Data Lab, the GIZ Sector Network Rural Development Asia and the Pacific, the GIZ Sector Network Rural Development Africa, and Prof. Jadu Dash of the University of Southampton, we trained 14 GIZ teams working on climate change mitigation and adaptation in eight countries in applying the DPPD method.
With five live sessions, weekly individual team mentoring and technical deep dives, this was the most in-depth training we’ve delivered so far.
At the end of each week, we reflected on the key learnings. Below we’ve compiled these weekly reflections that were initially published on the GIZ Data Lab blog in one single blog post.
For more information on the Masterclass, the teams and their use cases, visit the GIZ Data Lab blog.
Week 1 — Thinking in solutions
We know it can be difficult to understand all the technical aspects of the DPPD method (define the unit of analysis, identify suitable data sources, figure out what data to use as control variables, access data and so on). But we sometimes forget how challenging it is for those new to the method to adopt a way of (conceptual) thinking that they might not be used to.
The conventional thinking in international development goes something like this: We identify a problem, analyze what is going on, devise and implement a plan on how to fix what is broken and, if all goes well, there is going to be a positive outcome.
PROBLEM → ANALYSE → SOLVE
With DPPD we take a different path. Here we assume that a solution to a given problem exists. We try to find those who own the solution and help them replicate or scale it.
SOLUTION → IDENTIFY → SCALE
Instead of asking “what problem can we solve here”, DPPD requires us to think about how to identify (and scale) existing solutions and work with the individuals who developed them. For development practitioners applying the DPPD method that means going from being the creator of a solution to becoming a facilitator in the search for solutions.
We are not the first to apply this type of thinking. Practitioners of the Positive Deviance approach have long based their work on the premise that we should work with those individuals who achieve better results than their peers. The Honey Bee Network maintains a database of over one million ideas, innovations, and traditional knowledge practices. And the UNDP has built a whole network of labs across the globe to learn from local innovations to inform development interventions.
While week 1 of the DPPD Masterclass was all about helping the course participants shift from the conventional to a more asset-based, solution-oriented thinking, in week 2 we will be looking into the other core element of the method: leveraging digital data sources to aid in the identification of potential positive deviants.
Week 2 — Leveraging digital data
In the second week of the DPPD Masterclass, we focused on data mapping and how to identify potential data sources.
When applying the DPPD method, earth observation data (EO) specifically plays an important role. EO data provides information about the physical, chemical, and biological systems of the planet using remote sensing technologies. It is considered the most cost-effective technology able to provide data at a global scale. It can be acquired at low cost, over long periods of time, and thanks to the recent advances in remote sensing technologies, it is witnessing a growing availability at a high-resolution including coverage of low-income countries where other datasets are lacking. Applying the DPPD method in multiple domains, we learned that EO data can play an instrumental role in scaling the DPPD method.
This was also evident when we did a data mapping exercise with the participants during which we looked for the right data match with their climate change mitigation and adaptation use cases. More than 80% of the use cases had outcome indicators, i.e., a performance measure that could enable the identification of positive deviance within the target group, that could be captured using EO data. Based on the positive deviants identified using EO data in the first step, it is then possible to detect local solutions using supplementary (qualitative) data in a second step.
EO data is also suited to control for key contextual factors such as climate events, biophysical drivers, land cover, and to complement traditional data to develop high resolution spatial data on population distributions, demographics and dynamics.
The figure below presents a snippet of some data matching that we did to be able to capture contextual factors and possible outcome measures. It covered four main thematic groups which participants’ use cases were divided into: climate-resilience, nature conservation and restoration, climate-smart agriculture and pollution prevention.
Examples of possible EO-based outcome measures range from the use of remote sensing derived vegetation indices (e.g., SAVI, NDVI) to identify climate-resilient agricultural communities to finding healthier community-managed wetlands using Sentinel-2-based classification and change over time. We are also looking into using Sentinel-5p data to identify environmentally-friendly industrial parks and the use of Landsat to identify communities deforesting less than expected.
Attributes of EO data (high temporal, spatial and spectral resolution) make it possible to overcome common data accessibility and representation limitations while being able to capture the potential gains of using big data in positive deviance such as reducing the cost, time and risk of measuring performance at large scale.
Of course, limitations must be acknowledged given that EO data is applicable only in DPPD projects where the impact of human behaviors and practices on natural and built environments can be observed and measured remotely. It nonetheless remains a low-hanging fruit for the application of DPPD in climate change mitigation and adaptation given its accessibility, coverage and low cost.
Week 3 — Assessing desirability
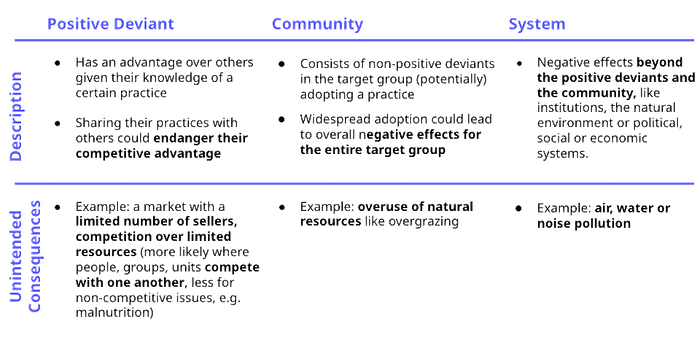
In week three of the Masterclass, we worked with the teams on their desirability assessments. This involves the responsible use of data as well as identifying (and mitigating) potential unintended consequences that might result from others adopting the practices of positive deviants.
Such negative effects can happen on three levels:
- the positive deviant that has developed a practice leading to outperformance,
- the community of largely non-positive deviants that might adopt the practice,
- the wider systems that the positive deviant and the community are embedded in or connected with.
Positive Deviants
It’s generally safe to assume that positive deviants are not aware of their innovativeness and/or of the success of their uncommon practices and strategies. In some cases, however, they may be aware of it and may choose not to share their strategies with others in their community for fear of losing their competitive advantage or depleting a resource they alone are aware of. This is less likely an issue where cultural norms dictate against competitive strategies, such as child malnutrition or health care, but it might be problematic in areas where people more overtly compete with one another.
Communities
Here we ask to what extent a practice would really lead to positive sustainable effects for the entire community if adopted by non-positive deviants. For instance, scaling the practice of a positively-deviant pastoralist might lead to an increase in pastoral activities and livestock numbers. However, over time this might result in a shortage of grazing land, eventually leading to the obsolescence of the positive practice.
Systems
While difficult, it is also worth reflecting on potential negative effects beyond the positive deviants and the community, such as the natural environment and political, social or economic institutions and systems. Examples include air, water or noise pollution.
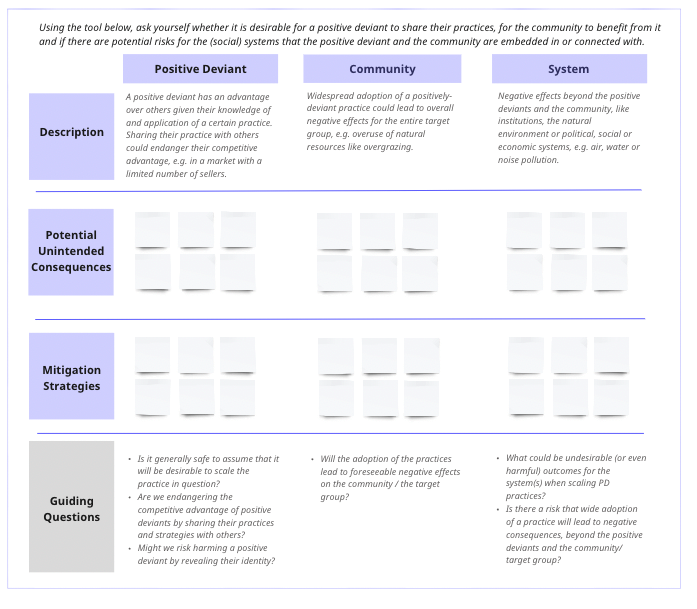
We then walked the participants through examples like the one pictured below. This one is based on a case from Bangladesh where the introduction of shrimp aquaculture seemed like an effective climate-change adaptation, but which has caused huge unintended consequences.
We also discussed mitigation strategies before the teams then worked on their use cases to identify and assess potential unintended consequences and ways to avoid or mitigate them using the tool below.
In next week’s session, we will talk about Stage 2 of the DPPD method where the teams will learn to determine and validate positive deviants using homogeneous grouping and performance measurement techniques.
Week 4 — Mapping variables
In Session 4 we discussed Stage 2 of the DPPD method (determine positive deviants) which looks into performance measurement, followed by homogeneous grouping and positive deviant identification, and finally the preliminary validation of the identified positive deviants.
A range of factors influence to what extent an individual outperforms and therefore might be considered a positive deviant. This includes their distinct strategies and practices, but also factors that are given, e.g. soil quality, or are beyond the influence of the individual, e.g. government subsidies and other interventions.
Analyzing and controlling for these factors is important to make sure we are able to identify true positive deviants based on their uncommon, but successful behaviors and not due to structural and contextual factors.
This is where the DPPD Variable Mapping tool comes in.
We introduced the tool to help participants map out the possible control and independent variables in order to select the most suitable variables for the homogeneous grouping and the positive deviant identification steps of Stage 2 as well as the identification of positively deviant behaviors in Stage 3.

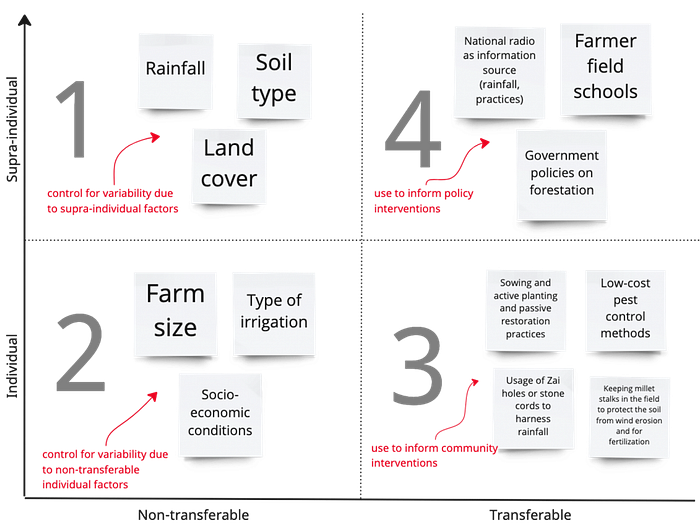
The X-axis shows to what extent the predictor variable is behavioral and could therefore potentially be transferred from one person, community or unit to another. The further to the right, the more the behavior can be shared with other members belonging to the same homogeneous group.
The Y-axis shows to what extent the predictor variable is individual or supra-individual (beyond the control of the individual). The more the variable is supra-individual and non-behavioral, the more suitable for homogeneous grouping it becomes.
Using this tool you will be able to categorize and map the variables into four main types:
- Supra-individual, non-transferable factors (quadrant 1) allow you to create homogeneous groups based on factors beyond the control of individuals that cannot be changed but which influence outcomes, mainly physical factors. Examples include using rainfall, temperature or soil quality to create agricultural peer-groups for the identification of positively deviant farmers in each group separately.
- Individual, non-transferable factors (quadrant 2) are used to control for individual-level factors that can influence outcomes but cannot be changed, e.g. age. Those variables need to be controlled for when identifying positive deviants within each homogeneous group to ensure that the variance in performance is mainly due to transferable factors. They will act as independent variables in the prediction of performance given which positive deviants will be identified from the residuals i.e. how far they are — in a positive way — from what was predicted.
- Individual, transferable factors (quadrant 3) refer to all the behaviors of positive deviants that can be shared with other community members, e.g. soil and water conservation techniques. Those variables are used (after the positive deviant identification) in inferential statistical tests and regression analysis to check if they have a significant effect on the positive outcomes.
- Supra-individual, transferable factors (quadrant 4) are variables that are beyond the control of individuals and can be transferred at the system level, e.g. government policies. Those variables are also used in inferential statistical tests and regression analysis to identify key differentiators and determinants of positively-deviant performance.
Selecting which variables are better suited for which step in the analysis is one of the toughest decisions to make when applying the DPPD method. The Variable Mapping tool can make this process easier as it provides a simple way to distinguish variables based on their role in either identifying or explaining deviance.
Week 5 — Designing interventions
In the last session of the DPPD Masterclass, we provided the teams with an overview of all the remaining stages and learned from an expert how to design effective social and behavior change interventions.
In DPPD we differentiate between two different types of interventions:
- Community interventions focus on enabling and supporting positive deviants to share their positively-deviant strategies and practices with others.
- Policy interventions go beyond the sharing of individual practices and look at adjusting system-level factors that could influence outcomes.

To demonstrate how the choice and design of the interventions follow from the analysis of data and synthesis of insights from the previous stages, we applied the DPPD Variable Mapping tool that we introduced in Session 4 (see the blog post below) using the DPPD food insecurity in Niger pilot project as an example.
We control for supra-individual factors that are not transferable (quadrant 1) through homogeneous grouping and for individual factors that are not transferable (quadrant 2) within the homogeneous groups.
Quadrants 3 and 4 will help uncover factors that could inform interventions at different levels. They can be community interventions that enable people to share, learn and practice the behaviors of positive deviants, but also programs (e.g. low-cost pest control methods), policies or other interventions of support, training, financing that go beyond the replication of individual practices (e.g. government policies on forestation).
This blog post marks the end of the Masterclass which focused on the application of the DPPD method in climate change mitigation and adaptation. In the final session we covered the remaining three stages of the DPPD method which are concerned with uncovering positively-deviant strategies and practices, designing interventions and monitoring and evaluating their effects.
Following the Masterclass, the teams developed use case proposals demonstrating how they would go about applying the DPPD method in response to the climate change challenges they submitted upon applying for the Masterclass. We hope to see those proposals materialize into effective interventions in the coming year.
